The Inference Boom: Why AI's Next Frontier Demands Unprecedented Compute
Description: The article highlights the shift in AI compute demand from training to inference, driven by the rise of advanced reasoning models, personalization, and autonomous LLM agents. This surge in real-time computational needs is poised to redefine AI infrastructure and scalability.
- Inference time compute
- Inference
- Compute
- scaling laws
- hardware
- demand
- agents
- synthetic data
1. Introduction
Large Language Models (LLMs) have seen remarkable progress in recent years, driven by breakthroughs in transformer architectures, scaling laws, and the availability of massive datasets. The focus on ever-larger model sizes and expansive training corpora has undeniably catalyzed major leaps in capabilities—from improved natural language understanding to more sophisticated forms of reasoning. However, as these models mature and move from research laboratories into real-world applications, the balance of computational demand is shifting.
While training large models once absorbed the bulk of the AI community's resources, attention is rapidly pivoting to the challenges of inference—the runtime process that powers each interaction with an LLM. As organizations deploy these models in products ranging from chatbots to advanced reasoning agents, the sheer volume of user interactions and the growing complexity of inference-time processing (e.g., multi-step reasoning, longer context windows, or on-the-fly adaptation) create a scenario where inference emerges as the main consumer of computational resources. This can be backed by multiple industry veterans in this space such as Jensen Huang CEO of Nvidia who says that inference will be a billion times larger than training. We will explore if it he was exaggerating or not since training is already over $6 Billion Market as of 2024.
This report examines this transition in detail. First, we review traditional training cycles and the scaling laws that historically drove performance gains. Next, we explore how data limitations and the growing need for synthetic data have introduced new pressures on model development. We then discuss post-training (fine-tuning) and inference-time scaling laws—two areas that, while less commonly spotlighted than pre-training, are now proving pivotal in enabling models to perform more advanced tasks. Finally, we consider the rise of reasoning models and LLM agents, applications that actively rely on complex inference mechanisms and continuously adapt to users or tasks. Together, these developments paint a clear picture of why inference demand is set to skyrocket in the coming years, reshaping how we design, deploy, and manage large-scale AI systems.
2. Historical Context: Where Compute Has Been Spent To Drive Performance
2.1. Traditional Training Cycles
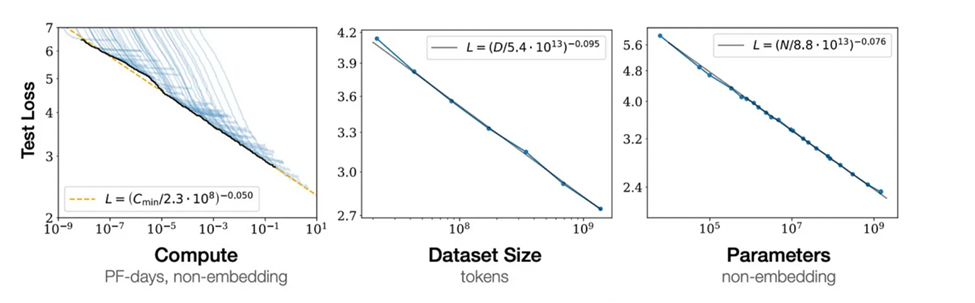
Historically, the bulk of AI compute expenditure went toward model training. Beginning with transformers in 2017, each new iteration of state-of-the-art language models demonstrated that scaling up both model size (number of parameters) and training data volume led to consistent performance gains. This phenomenon, referred to as the scaling law, was famously articulated by OpenAI and others in seminal papers that showed near power-law relationships between compute, data, model size, and loss metrics.
2.1.1. Pre-Training Scaling Laws
Pre-training involves training a model on a massive corpus of text (or multimodal data, in some cases) to learn generalized language representations. In one sentence: Pre-training scaling laws state that increasing model size and the volume of high-quality data leads to significant improvements in model performance.
- Historic Performance Gains: GPT-3's breakthrough in 2020 showed that a 175-billion-parameter model could perform tasks (e.g., summarization, translation, question answering) that previously required specialized fine-tuning. From GPT-2 (1.5B parameters) to GPT-3 (175B parameters) and beyond, performance across various language benchmarks skyrocketed, spurring ever-larger model deployments like GPT-4, Claude Sonnet, Llama 3 and more.
- Hitting a Wall: Data Scarcity: As these models grew, so did their appetite for high-quality text data. However, the internet's most relevant and high-quality text sources are finite. Experts estimate we have tapped into a significant portion of publicly available high-quality data, meaning continuing to grow models indefinitely has diminishing returns unless we can generate large amounts of synthetic data.
- Synthetic Data: With human-generated content reaching a saturation point, synthetic data (machine-generated text, carefully curated to maintain diversity and complexity) is becoming critical. This requirement alone represents a shift in how data is generated and utilized but does not change the reality that the next major cost sink—beyond the creation of synthetic datasets—will be in how these models are used in production, i.e., inference.
2.2. Post-Training: Fine-Tuning and Alignment
After a model is pre-trained, it undergoes fine-tuning or alignment, often on task-specific data or through techniques like Reinforcement Learning from Human Feedback (RLHF) to improve its responses for more practical or safer real-world use. In essence, post-training optimizes a pre-trained model for specific use cases or deployment environments and makes it more useful to the end user.
2.2.1. Post-Training Scaling Laws
Post-training scaling laws show that after a large model is pre-trained, dedicating additional compute to specialized tasks, alignment, and advanced instruction tuning can yield disproportionately large gains in performance.
- Performance Gains and “Finished Products”: Post-training transforms a general model into a specialized or aligned one—dramatically improving user-facing metrics like factual accuracy, reasoning, creativity, and safety.
- Increased Flops: Until a few months ago, post-training utilized only a small percentage of compute, but with the newer series of reasoning models (which we will discuss more in detail during the next section), this has started to far surpass the amount of compute required in the pre-training phase. During this phase, advanced techniques like chain-of-thought or multi-step reasoning emerge. Thus, post-training compute has cemented itself as the second scaling law leading to increased performance.
3. The Newest Frontier: Inference-Time (Test-Time) Compute
While training-based scaling laws have traditionally garnered all the attention and capital, a more recent development indicates that inference-time compute may be the next critical dimension. In essence, these are models that “think” or compute more during inference, rather than being constrained to a single forward pass. Simply put, the more compute (or time they get to think) during inference, the better their performance.
3.1. Emergence of Reasoning Models
“Reasoning models” apply iterative or multi-step reasoning at test time, effectively running multiple forward passes internally to refine their answers. This approach has been shown to yield superior results on tasks like coding, complex math, and scientific problem-solving.
- Test-Time Compute Scales Performance: One of the groundbreaking realizations is that giving models more computational budget (i.e., more inference steps) can significantly enhance their output quality. This is akin to letting the model think through a problem more thoroughly, akin to how humans might reason step-by-step.
- Cost Implications: An example cited is the cost per token for o1 being nearly 60x that of GPT-4, despite both being powered by similarly sized underlying models. Why? Because o1 leverages a more extensive inference-time reasoning process. This is why Sam Altman says they are losing money on their ChatGPT pro $200 a month subscription despite being 10x the cost of the regular subscription per user.
- Hardware Sharing: Typical LLM inference can be batched so that multiple users share a single GPU node efficiently (e.g., 40 users per H100 node). But with advanced test-time reasoning requiring larger key-value (KV) caches and longer sequence lengths, the same node might only serve ~10 users. For the same user load, you now need about 4× the hardware—a major driver of hardware demand.
- On January 20, 2025, Chinese AI startup DeepSeek released its R1 model under the open MIT license. This model exemplifies the latest trend in reasoning models, balancing performance and cost. DeepSeek-R1 demonstrates performance comparable to leading models like OpenAI's o1 while being significantly more cost-efficient. It employs advanced multi-step reasoning to excel in coding, math, and scientific problem-solving. DeepSeek's competitive pricing and efficient design make it a compelling option, especially as reasoning models grow increasingly hardware-intensive due to expanded test-time compute requirements. These advancements suggest a shift towards accessible and scalable AI reasoning capabilities, redefining the economics of high-performance AI.
4. Another Emerging Scaling Law: Inference-Time Fine-Tuning
One of the most exciting frontiers is a type of continuous learning or in-session learning that occurs during inference. Early signals of this approach can be found in experiments by major AI labs (like Google's new "Transformer 2.0" architecture):
- Long-Term and Permanent Memory: Inspired by the human brain, these models can store information during inference and selectively forget or retain it.
- Adaptive Focus: The model dedicates more compute to novel or "surprising" information, improving its adaptability in real-time and reducing redundancy for well-known data.
- Context Window Solutions: Traditional transformers are constrained by fixed context windows, but new architectures propose dynamic context windows, effectively working around the memory limitations of standard self-attention.
- Personalized Models: This approach allows for on-the-fly adaptation to a user's style or context, creating a personalized or custom model experience without full-blown offline fine-tuning.
All of these directions point to a future where each inference session involves some component of “fine-tuning” or adaptation, which dramatically increases inference compute requirements.
5. LLM Agent: The Next Major Catalyst
5.1. What Are LLM Agents?
LLM agents that combine language models with additional tools (e.g., knowledge graphs, plugins, external APIs) to perform complex tasks without human intervention. Examples include multi-step reasoning pipelines, ChatGPT plugins, Auto-GPT variants, and more general “autonomous” AI systems.
5.2. Agents of Reasoning Models
When you couple reasoning models (that already use iterative inference) with agent paradigms (where the model operates in loops, querying external tools, updating its state, refining its plan), the computational load escalates exponentially:
- Continuous Interactions: An agent might run hundreds or thousands of small inference steps to achieve a single high-level goal.
- Unbounded Task Complexity: As tasks get more complex (e.g., multi-day or multi-week tasks), the agent’s inference volume grows proportionally.
Given that large organizations are already exploring or piloting such agent-based systems for everything from code debugging to financial analytics, the hardware needs for inference are set to skyrocket.
5.3. Service-as-a-Software: Unlocking a Multi-Trillion-Dollar Opportunity
The transition from traditional software to AI-driven Service-as-a-Software is transforming markets, expanding beyond software into the vast $10T+ services economy. Over the years, the market has evolved from a $350B software market with a $6B cloud segment in 2010 to $650B in software and $400B in cloud by 2024, with the emerging AI software market still at an early $3B.
This shift enables outcome-based revenue models, where AI agents like Sierra autonomously resolve customer support issues and charge based on successful resolutions, replacing traditional per-user pricing.
Additionally, AI-driven tools like XBOW (AI Pentester) turn costly, manual tasks like penetration testing into scalable, affordable services, broadening niche markets into continuous, AI-driven solutions. AI agents are disrupting industries such as legal (Harvey), medical (Abridge), and CRM (Day.ai), redefining workflows and pricing structures.
As inference costs drop and reasoning models advance, the adoption of automated solutions in the services economy will accelerate, driving exponential growth in the AI market.
6. Why Inference Demand Is About to Explode
Despite the rapid growth in public awareness of large language models, mainstream adoption is still in its early stages. Most businesses are only beginning to explore AI’s potential; many have not yet fully integrated advanced capabilities like multi-step reasoning, personalization, or agent-based functionality into their workflows. As these use cases mature and become more widespread, demand for inference will grow at an unprecedented rate. Below are key factors driving this surge:
- Expanding User Base: Large-scale deployments of LLM-powered tools already handle millions of daily requests, and this number is set to grow exponentially as more enterprises integrate AI into workflows.
- Rising Complexity of Inference: Advanced reasoning mechanisms (e.g., chain-of-thought or iterative inference) require multiple computational steps per query, multiplying the compute cost for high-quality outputs.
- Real-Time Personalization: Lightweight, continuous fine-tuning during user interactions enhances adaptability and satisfaction but increases compute demands for each session.
- Proliferation of AI Agents: Autonomous AI agents engage in complex, multi-step tasks and dialogues, requiring thousands of inference calls per high-level objective. These agents may also embed training-while-inferencing mechanisms for real-time adaptation.
- Iterative Reasoning and Adaptation: Models now dedicate compute to refining responses step-by-step, akin to human-like reasoning, which significantly amplifies resource consumption.
As organizations move beyond simple chat-based use cases to more persistent, agent-based, and personalized deployments, the compute load for inference will skyrocket. The combination of massive user bases, increasingly intricate inference processes, and the growing demand for adaptive, “always-on” AI agents makes it clear that inference capacity—and the infrastructure that supports it—will be at the heart of the next wave of AI advancements.
7. Outlook
The AI industry stands at a pivotal moment where inference is transitioning from an afterthought to a primary compute bottleneck. Veterans in the field—such as NVIDIA CEO Jensen Huang—have predicted that inference will be vastly larger than training. The reasons are clear:
- Data Limitations constrain indefinite model growth, pushing development toward efficient inference.
- Advanced Post-Training consumes significant compute but ultimately funnels users into inference-driven applications.
- Inference-Time Reasoning and Fine-Tuning drastically increase compute per interaction, especially for multi-step or agent-based systems.
- LLM Agents promise to scale usage exponentially as they operate continuously and autonomously.
In essence, every user query, personalization step, or agent decision translates into real-time computational load—and these interactions will number in the billions. As organizations race to deploy more capable, always-on AI services, those who master scalable inference infrastructure will define the industry’s future, validating the predictions of market leaders who foresee an explosion in inference demand that may indeed dwarf training in the years ahead.